
Google Cloud の Batch でファイルを解凍してみる

Google Cloud データエンジニアのはんざわです。
先日、Google Cloud の Batch を使用する機会があり、その際に調べた内容を本ブログで紹介します。
Batch の概要
Batch とは、Google Cloud で大規模なバッチ処理を実行するフルマネージドサービスです。
1つ以上のタスクとその他の要件(実行するサービスアカウントやリージョンなど)で構成されるジョブを定義します。
裏側は Compute Engine で構成されており、各ジョブはリージョンマネージドインスタンスグループ(MIG)で実行されます。
必要に応じて、各タスクに割り当てるコンピューティングリソース(vCPU、メモリ、追加のブートディスクストレージ)を柔軟に指定することができます。
Cloud Run jobs との比較
バッチ処理を実行する類似サービスに Cloud Run jobs というサービスが存在します。
それぞれの機能を比較すると、以下のようになります。
-
Cloud Run jobs
- メモリの上限が 32 GB
- CPU の上限が 8 vCPU
- GPU の利用が不可能
- 最大実行時間が 1 時間
- 裏側は Cloud Run で構成されている
- コンテナでジョブの実行が可能
- 構成の設定が簡単
- デプロイした関数を再度呼び出すことが可能
- Workflows からの呼び出しが同期
-
Batch
- メモリの上限が 896 GB(1つのタスクで)
- CPU の上限が 224 vCPU(1つのタスクで)
- GPU の利用が可能
- 最大実行時間が 14 日
- 裏側は Compute Engine で構成されている
- コンテナかスクリプトでジョブの実行が可能
- 構成の設定が複雑
- 一度作成したジョブを再度呼び出すことが不可能、使い捨てになる
- Workflows からの呼び出しが非同期
基本的なバッチ処理を実行したい場合は、Cloud Run jobs で十分かなと思います。
一方で、以下の条件に当てはまる場合は、Batch を選択すると良いと思われます。
- メモリや CPU が Cloud Run jobs の上限では足りない
- GPU を利用したい
- 最大実行時間が 1 時間では足りない
- コンテナの使用を避けたい
補足ですが、2024 年 10 月 24 日時点で Cloud Run services で GPU がプレビュー機能として追加されました。
現時点で Cloud Run jobs の GPU のサポートはされていませんが、将来的にサポートされるようになれば Cloud Run jobs を選択する機会が増えるかもしれません。
ジョブについて
前述したとおり、ジョブは1つ以上実行するタスクで構成されます。
スクリプトまたはコンテナイメージに基づくジョブの作成と実行が可能です。
再利用性を考慮するのであれば、コンテナイメージに基づいたジョブを作成すると良いでしょう。
参考:コンテナジョブを作成する
一方で、コンテナ化されていないスクリプトの引っ越しやコンテナの知見が無い場合は、スクリプトに基づいたジョブを作成すると良いでしょう。
ジョブの作成について
ジョブの作成で指定可能なすべてのパラメータは projects.locations.jobs の REST Resource ドキュメントで確認できます。
実行したいジョブ構成を定義した Json のファイルを作成し、gcloud CLI や Batch API に渡すことでジョブを実行することが可能です。
また、公式ドキュメントにも記載のとおり、以下の注意点があります。
できるだけ Batch を使用する際は、gcloud CLI または Batch API でジョブを作成するようにしましょう。
Batch を触ってみる
早速、Batch を触ってみたいと思います。
やりたいこと
今回やりたいことは、以下のとおりです。
- バケットから圧縮されたファイルを取得し、解凍したファイルを別のバケットに移す
- ジョブのタスクはスクリプトを使用する
- ジョブの構成はシンプルな設定にする
事前準備
検証で使用するリソースを準備します。
1. サービスアカウント
Batch を実行するサービアカウントを新たに作成し、以下の3つの権限を付与します。
- バッチエージェント報告者(
roles/batch.agentReporter) - バケットのストレージ管理者(
roles/storage.admin) - プロジェクトに対するログ書き込み(
roles/logging.logWriter)
# サービスアカウントを作成
$ gcloud iam service-accounts create sa-batch
# roles/batch.agentReporter の権限を付与
$ gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:sa-batch@<PROJECT_ID>.iam.gserviceaccount.com" \
--role="roles/batch.agentReporter" \
--condition None
# roles/storage.admin の権限を付与
$ gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:sa-batch@<PROJECT_ID>.iam.gserviceaccount.com" \
--role="roles/storage.admin" \
--condition None
# roles/logging.logWriter の権限を付与
$ gcloud projects add-iam-policy-binding <PROJECT_ID> \
--member="serviceAccount:sa-batch@<PROJECT_ID>.iam.gserviceaccount.com" \
--role="roles/logging.logWriter" \
--condition None
2. Cloud Storage
以下のコマンドで圧縮されたファイルを保管するバケットと解凍したファイルを保管するバケットを作成します。
# 圧縮されたファイルを保管するバケット
$ gcloud storage buckets create gs://hanzawa-yuya-compressed-files \
--location=asia-northeast1 \
--uniform-bucket-level-access
# 解凍したファイルを保管するバケット
$ gcloud storage buckets create gs://hanzawa-yuya-uncompressed-files \
--location=asia-northeast1 \
--uniform-bucket-level-access
3. 圧縮ファイルの作成とアップロード
以下のコマンドで CSV ファイルを作成し、圧縮します。
さらにそのファイルを圧縮されたファイルを保管するバケットにコピーします。
$ echo "id,name" > sample.csv && echo "1,apple" >> sample.csv
$ gzip sample.csv
$ gcloud storage cp ./sample.csv.gz gs://hanzawa-yuya-compressed-files/test/
Batch
Batch の準備は gcloud CLI 経由で行います。
実行するスクリプトの内容は、以下のとおりです。
INPUT_BUCKET からファイルをコピーし、解凍したファイルを OUTPUT_BUCKET に移動する処理となっています。
#!/bin/bash
echo "----"
echo $FILE_PATH
echo "----"
set -e
FILE_NAME=$(basename "$FILE_PATH")
FILE_DIR=$(dirname "$FILE_PATH")
echo "Downloading $FILE_NAME from $INPUT_BUCKET"
gcloud storage cp gs://$INPUT_BUCKET/$FILE_PATH ./tmp/
echo "Decompressing $FILE_NAME..."
gzip -d ./tmp/$FILE_NAME
BASE_NAME="${FILE_NAME%.*}"
# 解凍後のファイル名
DECOMPRESSED_FILE="./tmp/${BASE_NAME}"
echo "Uploading $BASE_NAME to $OUTPUT_BUCKET/$FILE_DIR"
gcloud storage cp $DECOMPRESSED_FILE gs://$OUTPUT_BUCKET/$FILE_DIR/
echo "Process completed successfully."
以下が、実行したいジョブを定義したジョブファイルになります。
これらのシェルスクリプトやジョブファイルを gcloud CLI に渡します。
{
"taskGroups": [
{
"taskSpec": {
"computeResource": {
"cpuMilli": "500",
"memoryMib": "500"
}
},
"taskCount": 1,
"parallelism": 1,
"taskEnvironments": [
{
"variables": {
"FILE_PATH": "test/sample.csv.gz",
"INPUT_BUCKET": "hanzawa-yuya-compressed-files",
"OUTPUT_BUCKET": "hanzawa-yuya-uncompressed-files"
}
}
]
}
],
"allocationPolicy": {
"location": {
"allowedLocations": ["regions/asia-northeast1"]
},
"instances": [
{
"policy": {
"machineType": "e2-micro",
"provisioningModel": "STANDARD"
}
}
],
"serviceAccount": {
"email": "sa-batch@<PROJECT_ID>.iam.gserviceaccount.com"
}
},
"logsPolicy": {
"destination": "CLOUD_LOGGING"
}
}
動かしてみる
では、実際に動かしてみましょう。
gcloud CLI でジョブを作成する場合、gcloud beta batch jobs のコマンドからジョブを作成することができます。
$ gcloud beta batch jobs submit \
--location asia-northeast1 \
--config ./job.json \
--script-text "$(cat ./script.sh)"
以下のようにジョブの実行履歴から正常に処理が行われていることがわかります。
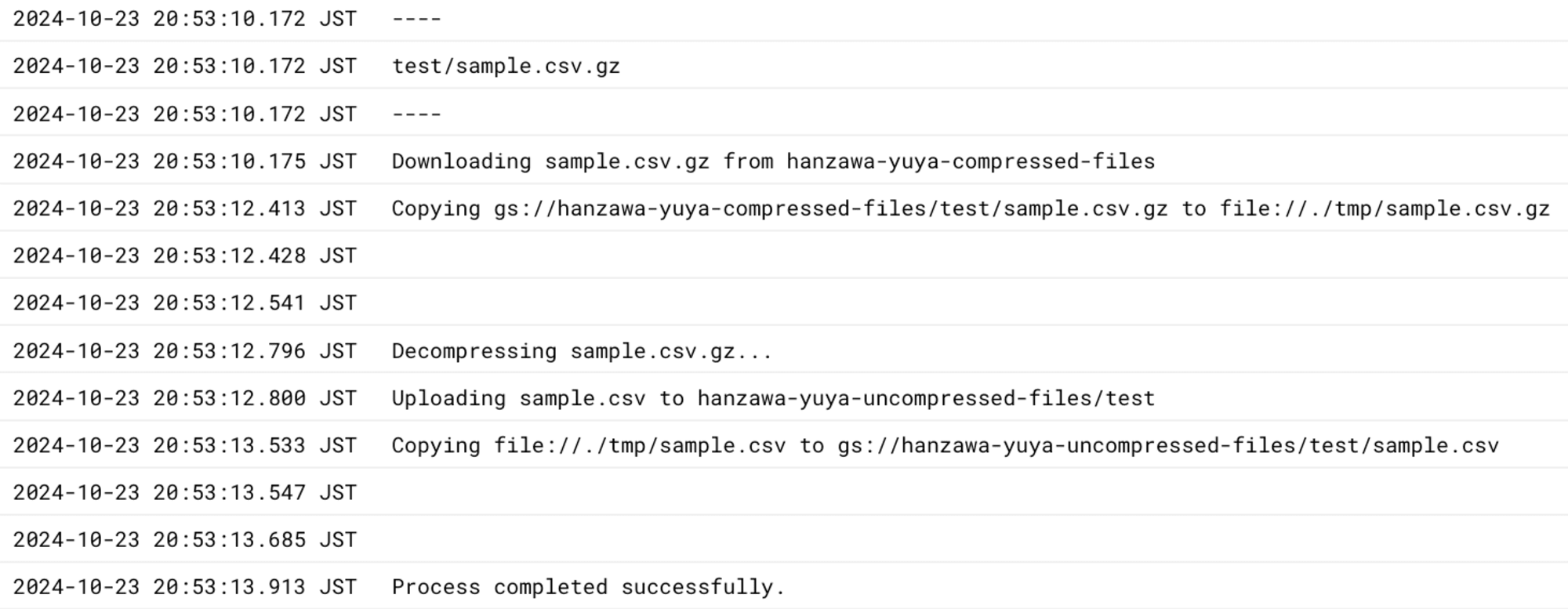
また、解凍したファイルを保管するバケットも確認し、解凍されたファイルが正常にアップロードされていることが確認できました。
$ gcloud storage ls gs://hanzawa-yuya-uncompressed-files/test/
> gs://hanzawa-yuya-uncompressed-files/test/sample.csv
料金
Batch の料金はジョブで使用される課金対象の Google Cloud のリソース(Compute Engine など)に対してのみ課金されます。
サービスの仕様上、おそらく課金額の大部分は Compute Engine の課金になると思われます。
各マシンタイプの料金は以下のドキュメントを参考にしてください。
制限や注意点
Batch 使用するにあたっての注意点は以下のドキュメントを参考にしてください。
個人的に最も気になったのが以下の点です。
2 つ目は、リソースの可用性エラーにより、必要なリソースのいずれかが現在の需要に比べて容量が少ない場合、ジョブが遅延または失敗する可能性が高くなります。 そのため、より少量でより共通のリソースを必要とし、リージョン内のどのゾーンでもジョブの実行を制限しない場合、ジョブはより早く実行される可能性があります。
参考元:ジョブの作成と実行の概要
各リージョン毎に利用可能なリソースにばらつきがあります。
容量が少ない(= 高価なマシンタイプ?)の場合、ジョブの遅延や失敗する可能性が高くなるようです。
可能な限り、各コンピューティングリソースの無駄がないマシンタイプを選択すると良いと考えられます。
まとめ
今回のブログでは Google Cloud の Batch を紹介しました。
Cloud Run jobs ではカバーしきれないバッチ処理では、非常に有用なサービスだと思います。
そのようなユースケースがあった場合は、是非利用を検討してみてください。





